I recently had a situation where I needed to make sure the correct version of node is installed before one runs npm install. This is because one of the packages in our project has a dependency on a specific node version.
Another challenge was that I should still be able to work on multiple projects, each with their own node version dependency.
My mission is clear, let the games begin…
Solution
nvm
To address the issue of running multiple versions of node on one machine, use nvm (Node Version Manager).
nvm is a version manager for node.js, designed to be installed per-user, and invoked per-shell.
I needed a windows version, and the nvm Readme.md pointed me to nvm-windows (Download nvm-setup.zip).
Similar (not identical) to nvm, but for Windows.
check-node-version
To verify the node version per JavaScript project, I found this npm package check-node-version. It allows you to verify the node version via CLI (Command Line Interface) or programmatically. I used both ways, just because I had two projects with different requirements.
Verify node version via CLI
I used this approach on a project where the project could not even install packages if you had an incorrect node version. I had to check the node version without having the luxury of npm install.
How do one use a npm package without executing npm install? … npx
This command allows you to run an arbitrary command from an npm package (either one installed locally, or fetched remotely), in a similar context as running it via npm run.
Steps to check node version between v10.x (including) and v11.0.0 (excluding)
use engines in your package.json to add a specific node version, or a range, to your project.
if (result.isSatisfied) { console.log("All is well."); return; }
console.error("Some package version(s) failed!");
for (const packageName ofObject.keys(result.versions)) { if (!result.versions[packageName].isSatisfied) { console.error(`Missing ${packageName}.`); } } }
With the knowledge of nvm, I’ve update check_node_version.js with some instruction to install and use nvm. Give your dev team instructions on how to solve the problem, they will love you for it. 😁
check_node_version.js: An example of the version check with instructions to solve the issue for windows users…
When you run npm install, the preinstall will execute requirements-check, and when all is good it will continue installing the project packages. If the node verification failed, the packages will not be installed.
Verify node version programmatically
install check-node-version as a dev dependency:
1
npm install check-node-version -D
use engines in your package.json to add a specific node version, or a range, to your project.
When you run npm install, your packages will be installed first, and after that postinstall will execute requirements-check to verify the correct node version.
One dream I have to even make this better, is to show the instructions with an added question: Would you like to download nvm and install the missing node version? [Y]es / [N]o. (There is some homework for you )
Final thoughts
When you add any breaking changes to your codebase, I believe it is your responsibility to help your teammates to fall into the pit of success without any cognitive overload.
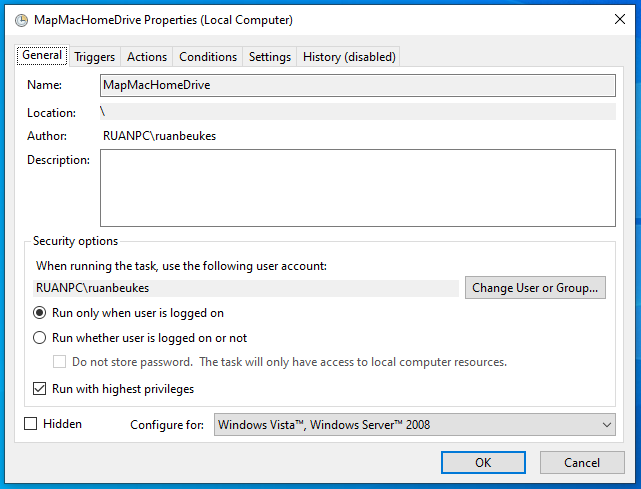
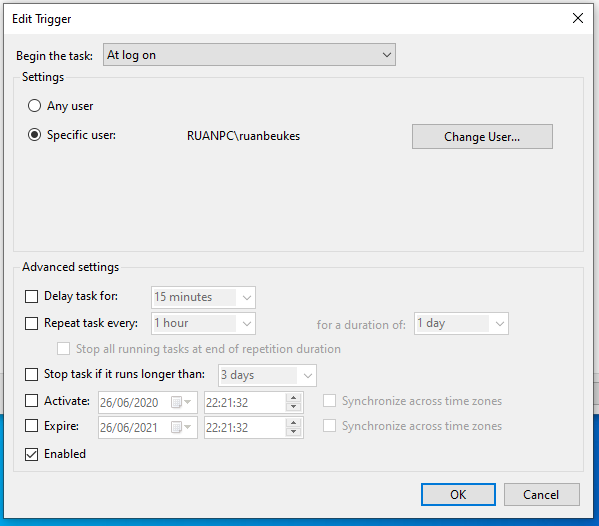
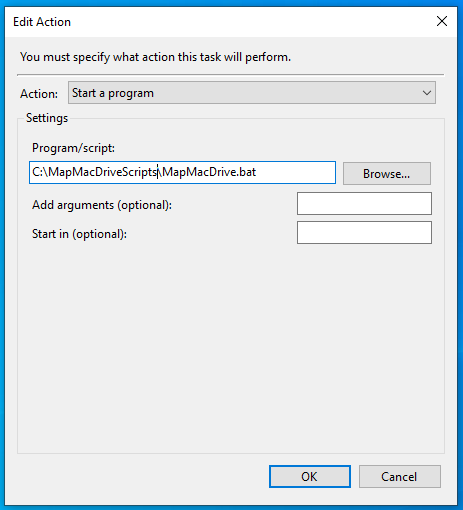
Then, in 2018, I made the jump to Mac. In order to save me a bit of trouble I invested in Parallels Desktop for Mac to support clients with .NET systems.
Problem
I needed my Parallels Windows Virtual Machine to access some files which lives on my Mac drive as Y:\.
When I run the Command Prompt without admin rights, everything works as advertised:
A few people started using the implementation and also suggested enhancements.
We started sharing code in the blog’s comments, then later I moved the code into a github gist angular-reactive-forms-helper.ts. At least the gist file is one step better than comments, right? :)
Then, early last week one of my mates contacted me with a change request. He created the suggested change in a gist file and shared it with me. I then updated his changes into my gist.
I had enough, this thing should be Open Source so that everyone can contribute.
It only took me two and a half years to finally move the code to github…LOL
Thus, npm package angular-typesafe-reactive-forms-helper was born.
I’ve been using AWS Cognito as the authentication piece to give users access to an Angular web project I’m working on. Everything worked as advertised and I was happy with the result, until I started testing my authentication service. That’s when things got interesting and I could not create a spy object on any of the Cognito classes.
Instead, I got…
1 2 3 4 5 6 7 8 9 10
AuthenticationService when .signInUser is working normally instantiate cognito AuthenticationDetails with correct user credentials FAILED Error: <spyOn> : AuthenticationDetails is not declared writable or has no setter Usage: spyOn(<object>, <methodName>) at <Jasmine> at UserContext.<anonymous> (http://localhost:9876/_karma_webpack_/src/shared/services/auth/authentication.service.spec.ts:33:40) at ZoneDelegate.invoke (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-evergreen.js:359:1) at ProxyZoneSpec.push../node_modules/zone.js/dist/zone-testing.js.ProxyZoneSpec.onInvoke (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-testing.js:308:1) at ZoneDelegate.invoke (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-evergreen.js:358:1) at Zone.run (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-evergreen.js:124:1) at runInTestZone (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-testing.js:561:1)
Quick Answer
Turns out you need to use Object.defineProperty and modify the property to be writable: true.
1 2 3 4 5 6 7 8
import * as AWSCognito from'amazon-cognito-identity-js';
In my case, Angular Monkey patched amazon-cognito-identity-js and the result is we can execute Object.defineProperty without TypeError: Cannot redefine property: AuthenticationDetails.
Mocking AWS Cognito is simple, now that I know :)
Code examples on how to mock AWS Cognito in Angular.
What is Object.defineProperty
Object.defineProperty is a function which is natively present in the Javascript runtime environment and takes the following arguments:
1
Object.defineProperty(obj, prop, descriptor)
With Object.defineProperty, one defines a new property directly on an object or modifies an existing property on an object.
In Javascript, standard properties (data member with getter and setter) are defined by accessor descriptor. Exclusively, you can use data descriptor (so you can’t use value and set on the same property):
accessor descriptor = get + set
get must be a function; its return value is used in reading the property; if not specified, the default is undefined, which behaves like a function that returns undefined.
set must be a function; its parameter is filled with Right Hand Side in assigning a value to property; if not specified, the default is undefined, which behaves like an empty function.
data descriptor = value + writable
value default undefined; if writable, configurable and enumerable (see below) are true, the property behaves like an ordinary data field.
writable - default false; if not true, the property is read only; attempt to write is ignored without error**
Both descriptors can have these members:
configurable - default false; if not true, the property can’t be deleted; attempt to delete is ignored without error**
enumerable - default false; if true, it will be iterated in for(var i in theObject); if false, it will not be iterated, but it is still accessible as public.
(** unless in strict mode - in that case javascript stops execution with TypeError unless it is caught in try-catch block)
In my case, I actually marked the Cognito.AuthenticationDetails constructor function as overridable (writable). But, you can only do that if configurable: true.
AuthenticationService when .signInUser is working normally instantiate cognito AuthenticationDetails with correct user credentials FAILED Error: <spyOn> : AuthenticationDetails is not declared writable or has no setter Usage: spyOn(<object>, <methodName>) at <Jasmine> at UserContext.<anonymous> (http://localhost:9876/_karma_webpack_/src/shared/services/auth/authentication.service.spec.ts:33:40) at ZoneDelegate.invoke (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-evergreen.js:359:1) at ProxyZoneSpec.push../node_modules/zone.js/dist/zone-testing.js.ProxyZoneSpec.onInvoke (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-testing.js:308:1) at ZoneDelegate.invoke (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-evergreen.js:358:1) at Zone.run (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-evergreen.js:124:1) at runInTestZone (http://localhost:9876/_karma_webpack_/node_modules/zone.js/dist/zone-testing.js:561:1)
Life was good and I continued working until the voice inside my head whispered:
“Why is this working…?”
Node behaves different to Angular
Although the chances of using a front-end library (amazon-cognito-identity-js) in a node.js server application is very low, I’ve created a quick test in node.js just to proof a point.
The test is following exactly what I’ve done in Angular, but without the extra package dependencies from Angular.
My investigation revealed Object.getOwnPropertyDescriptor(AWSCognito, 'AuthenticationDetails') returns configurable: false.
This is proof that AWS Cognito library is shipped with configurable: false.
Because it returns false, one would not be able to execute Object.defineProperty without an exception. The AWS team does not want you to fiddle with their implementation of AWSCognito.AuthenticationDetails.
describe('Investigaste Object.defineProperty of AWSCognito.AuthenticationDetails', () => { it('It should throw "TypeError: Cannot redefine property: AuthenticationDetails" because Object.getOwnPropertyDescriptor returns configurable: false', () => { console.log('Object.getOwnPropertyDescriptor(AWSCognito, "AuthenticationDetails"): '); console.log(Object.getOwnPropertyDescriptor(AWSCognito, 'AuthenticationDetails'));
// this will throw exception because of 'configurable: false', // meaning the AWS team does not want you to fiddle with this...and I agree, you shouldn't. Object.defineProperty(AWSCognito, 'AuthenticationDetails', { writable: true, value: 'foo' }); console.log(Object.getOwnPropertyDescriptor(AWSCognito, 'AuthenticationDetails')); });
Randomized with seed 26638 Started Object.getOwnPropertyDescriptor(AWSCognito, "AuthenticationDetails"): { get: [Function: get], set: undefined, enumerable: true, configurable: false } F
Failures: 1) Investigaste Object.defineProperty of AWSCognito.AuthenticationDetails It should throw "TypeError: Cannot redefine property: AuthenticationDetails" because Object.getOwnPropertyDescriptor returns configurable: false Message: TypeError: Cannot redefine property: AuthenticationDetails Stack: at <Jasmine> at UserContext.it (/Users/ruanbeukes/repos/MockCognitoInAngular/node-property-descriptor-investigation/test.spec.js:11:12) at <Jasmine> at runCallback (timers.js:705:18) at tryOnImmediate (timers.js:676:5)
1 spec, 1 failure Finished in 0.011 seconds Randomized with seed 26638 (jasmine --random=true --seed=26638)
I’m confused…I’m sure in my Angular test, before the property modification code, I logged the exact same thing and the result was configurable: true.
How is that possible?!
Angular’s Zone.js and Monkey patching
Angular uses zone.js to handle change detection. Because we have async code, Angular will Monkey patch all async APIs in order to managed the change detection. (See resources below for a more in-depth look at zone'js as it does more than just change detection, it also helps with debugging)
What is Monkey patching? By definition, Monkey patching is basically extending or modifying the original API. Now, zone.js re-defines all the async APIs like browser apis which includes set/clearTimeOut, set/clearInterval, alert, XHR apis etc.
amazon-cognito-identity-js will be re-defined by zone.js and also define the properties as configurable: true. Because it sets configurable: true, it explains why I can define/modify object properties in the Angular world but not in the node.js world.
Below is the code that changes configurable: false to configurable: true from zone-evergreen.js.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
functionrewriteDescriptor(obj, prop, desc) { // issue-927, if the desc is frozen, don't try to change the desc if (!Object.isFrozen(desc)) { /******** Ruan: This is where Angular does something different compared to node.js **/ desc.configurable = true; /************************************************************************************/ } if (!desc.configurable) { // issue-927, if the obj is frozen, don't try to set the desc to obj if (!obj[unconfigurablesKey] && !Object.isFrozen(obj)) { _defineProperty(obj, unconfigurablesKey, { writable: true, value: {} }); } if (obj[unconfigurablesKey]) { obj[unconfigurablesKey][prop] = true; } } return desc; }
Here is the stack trace when I’ve added a conditional breakpoint prop === 'AuthenticationDetails':
hub is an extension to command-line git that helps you do everyday GitHub tasks without ever leaving the terminal.
Why do I need hub?
It saved me the trouble to sign into Github, create the repository manually, just so I can clone it and work locally.
Current Workflow
Usually when I start a new Github repository, I’ll sign in and then create the new repository. The repository will then show me instructions on how to clone, HTTPS or SSH. Depending on my setup, I’ll clone and start coding.
My Use Case
I started a small throw-away-project, with a local git repository. A few hours later, I decided that the code might be useful and I wanted to formally push it to a remote source control server like Github.
My dream was to drop to the terminal and git -u origin master, that should create and push my local repository to my Github account…of course it is not that simple :)
I searched for a github cli tool and hub came up. It runs on macOS, Linux, Windows and a few others.
After I installed it, these are the steps I followed to create and push my local repository:
Open terminal and navigate to source code.
Enter: hub create
hub requested my github username. hub requested my github password. hub requested my Two-factor authentication code.
After the hub create command, I had a repository in Github…magic :)
git push -u origin master (yes, my dream line becomes a reality)
I also received a Github email notification: [GitHub] A personal access token has been added to your account
Conclusion
Although I only used the create command, I would encourage you to check out the hub manual for more interesting commands.
September 2018, exactly a year ago, I got this crazy idea to read one book a month for the next year. It is crazy because I’m not really your A+ student and I can always find something better to do, like sleeping, before I’ll read for fun :) The only time you’ll find me reading is when I’m doing some research on a coding problem or when I’m learning some new tech to put into practice.
Basically, I read for educational purposes…not for fun :)
Which brings me to my next problem, how do one hack the system if you don’t like reading?
You turn to audio books.
I signed up for an Amazon Audible account and started “reading” away. It’s a subscription model and your monthly fee provides you one book a month.
I vowed not to sacrifice my family’s time and added my own rule: Listen only on my daily commute to work. That is, 30-35 minutes of learning pleasure a day, 5 days a week.
I set out to find anything to drive my career forward, topics like: people and success, body language, goal setting, negotiation skills and leadership.
I was very focused…first month, done. Second month, done. Third month, something odd is happening…
The longer my journey continued, the more I discovered all these things I thought would drive my career, actually helped me more in my personal life. I realised all the extra time I put in was an investment into my family. It helped me be a better husband, dad and just be a better person in general.
Books
Below is a list of the books I read. I’m not going to give you a book review, you can read the review on Amazon :) Instead, I’ll highlight parts which I found useful in my life.
This book addressed my self doubt and changed my thinking to: I can do it. In fact, it pushed me to apply for a job I would never have considered before…and I got the job :)
You can apply this book to all aspects of your life. I applied some of the principles on my kids and was pleasantly surprised :) Word of caution, there is a fine line between influence and manipulation. Use your super power for good.
Two US Marines sharing their leadership knowledge and how to apply the same principles in your business. I later used some of those principles in my own life.
One bold statement from this book which might trigger interest:
Helped me on all aspects of my life! I would strongly advise to give this one a spin. It helps with handling those uncomfortable conversations. I found it very useful in everyday life.
Planning and setting goals. Of course there are more than just those two points, but they are my key focus points. A bit long but worked my way thought it.
It’s from an ex-FBI agent sharing years of experience on attracting and winning people over. I liked this one very much, it helped me to be a better person and to put others first.
How anyone can master the art and science of personal magnetism. This one helped me with a few ideas on public speaking. It also pushed me to sign up for my first public speaking event…even though it was just 5 minutes :)
The surprising truth about what motivates us. As always, Dan Pienk likes to use science to explain all his findings. This helped me on all aspects of life, work and family life.
An ex-FBI agent sharing some principles when he was a hostage negotiator. Fantastic book and I apply the principles daily at work and at home. It totally changed my point of view when you ask a question and the answer is “no”. The word “no”, is the beginning of the negotiation.
It also helped negotiating my kids into bed :)
We all negotiate everyday, you don’t have to like it, you just have to accept it.
Rating
Description
(A)
Awesome and enjoyed it a lot
(PG)
Pretty good
(G)
Good
Celebrations
Today I celebrate the completion of my personal goal I set 12 months ago. If I can do it, so can you! It does not have to be books, identify your own interest and commit to it for a year. You will surprise yourself.
Final thought
I believe life is about relationships, and I strive to treat anyone with respect regardless their social status or background. These books just highlighted my own believes again.